
Screenshot
How to Digest 1,000 Government Comments Before Breakfast
How do you make sense of hundreds of impact assessment comments without losing your mind? The old way involves clicking a link, reading a page, copying text into a spreadsheet, hitting the back button, and repeating that process until your eyes cross. It’s a slow, manual grind that makes true civic engagement exhausting.
So, we decided to cheat. Well, not cheat—automate.
In about five minutes, we built a custom web scraping tool specifically designed to tackle the massive amount of public data surrounding the NWMO Deep Geological Repository (DGR) Impact Assessment. Instead of navigating the Impact Assessment Agency of Canada (IAAC) website manually, we built a robot to do the heavy lifting for us.
The 5-Minute Build
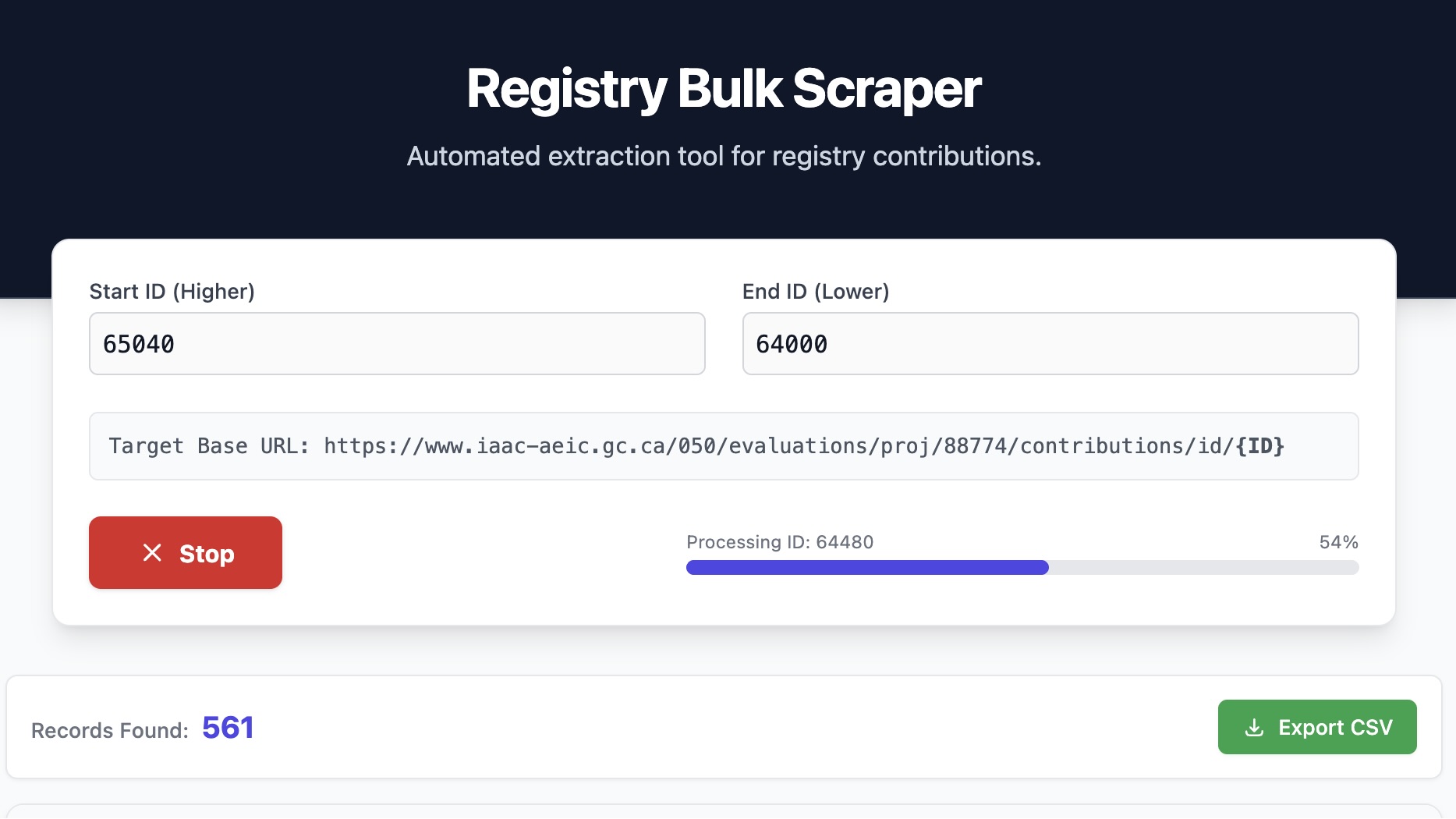
We spun up a lightweight web application that acts as a tireless research assistant. The concept is simple: the government registry stores comments with sequential IDs in their URLs. Our tool takes a starting ID (like 65040) and an ending ID (like 64000) and loops through them automatically.
It visits each page in the background, bypasses standard browser restrictions (thanks to a nifty CORS proxy), and reads the HTML source code instantly. It looks for specific patterns—bold labels like “Submitted by,” “Reference number,” and “Phase”—and extracts the text next to them. It even hunts down attachment links for PDFs. If a page is empty or an ID is missing, the tool simply notes it and moves on to the next one, faster than a human could ever move a mouse.
Data Democracy
The result? A clean, structured table populated with hundreds of records in real-time, all exportable to a CSV file with a single click.
This changes the game for analysis. Instead of treating each comment as an isolated web page, we now have a dataset. We can sort by date to see when engagement spiked. We can filter by “Submitted by” to see which organizations are most active. We can feed the raw text into an LLM to summarize sentiments or extract key themes across thousands of submissions.
Why Wait?
Open data shouldn’t just mean “technically available on the internet.” It should mean accessible, usable, and analyzable. Often, valuable public information is hidden behind clunky user interfaces and paginated lists that deter the average citizen.
Technology bridges that gap. Why wait weeks for an Access to Information request or spend days manual-entrying data when you can build a scraper in the time it takes to brew a coffee? With a little bit of code (and some AI assistance to write it), we can turn an overwhelming wall of bureaucracy into a transparent, manageable spreadsheet.
That’s how you power modern democracy—one scraped record at a time.




